

Publications
LingBot-Map: Geometric Context Transformer for Streaming 3D Reconstruction
LingBot-VA: Causal World Modeling for Robot Control
LingBot-World: Advancing Open-source World Models
LingBot-Depth: Masked Depth Modeling for Spatial Perception
Date
TitleSubtitle
First Authors Venue 
LingBot-Map Geometric Context Transformer for Streaming 3D Reconstruction
arXiv
LingBot-VA Causal World Modeling for Robot Control
arXiv
LingBot-World Advancing Open-source World Models
arXiv
LingBot-Depth Masked Depth Modeling for Spatial Perception
arXiv
Mixture of Contexts for Long Video Generation
ICLR
Video World Models with Long-term Spatial Memory
NeurIPS
Interspatial Attention for Efficient 4D Human Video Generation
SIGGRAPH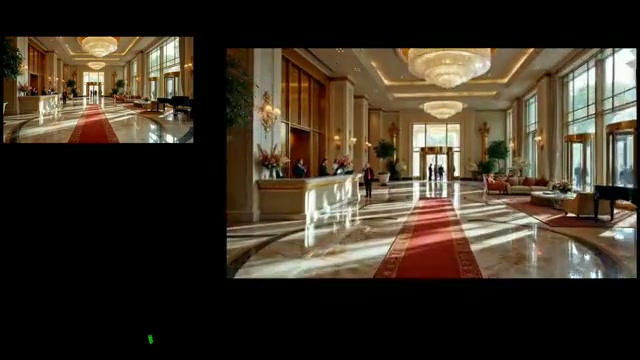
CameraCtrl II Dynamic Scene Exploration via Camera-controlled Video Diffusion Models
ICCV
GroomLight Hybrid Inverse Rendering for Relightable Human Hair Appearance Modeling
CVPR
FLARE Feed-forward Geometry, Appearance and Camera Estimation from Uncalibrated Sparse Views
CVPR
Edicho Consistent Image Editing in the Wild
ICCV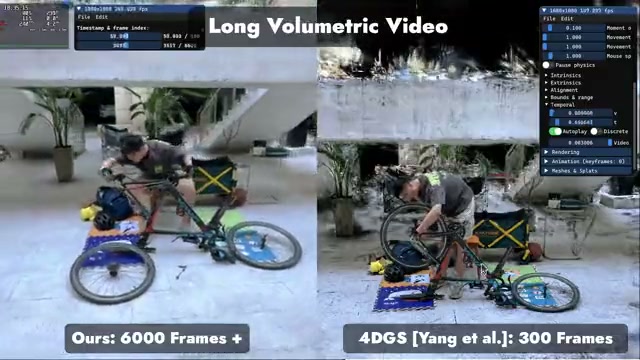
Representing Long Volumetric Video with Temporal Gaussian Hierarchy
SIGGRAPH Asia
FiVA Fine-grained Visual Attribute Dataset for Text-to-Image Diffusion Models
NeurIPS
Flow as the Cross-domain Manipulation Interface
✨ CoRL
3DitScene Editing Any Scene via Language-guided Disentangled Gaussian Splatting
ICLR
Collaborative Video Diffusion Consistent Multi-video Generation with Camera Control
NeurIPS
CameraCtrl Enabling Camera Control for Video Diffusion Models
ICLR
GRM Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation
ECCV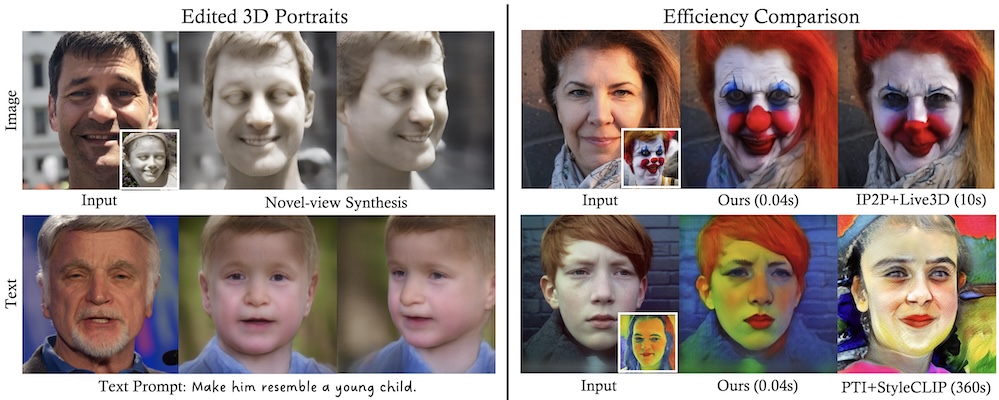
Real-time 3D-aware Portrait Editing from a Single Image
ECCV
BerfScene Bev-conditioned Equivariant Radiance Fields for Infinite 3D Scene Generation
CVPR
SceneWiz3D Towards Text-guided 3D Scene Composition
CVPR
Neural Body Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
✨ TPAMI
Gaussian Shell Maps for Efficient 3D Human Generation
CVPR
DMV3D:Denoising Multi-View Diffusion using 3D Large Reconstruction Model
✨ ICLR
PF-LRM Pose-Free Large Reconstruction Model for Joint Pose and Shape Prediction
✨ ICLR
Instant3D Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model
ICLR
Exploring Sparse MoE in GANs for Text-conditioned Image Synthesis
arXiv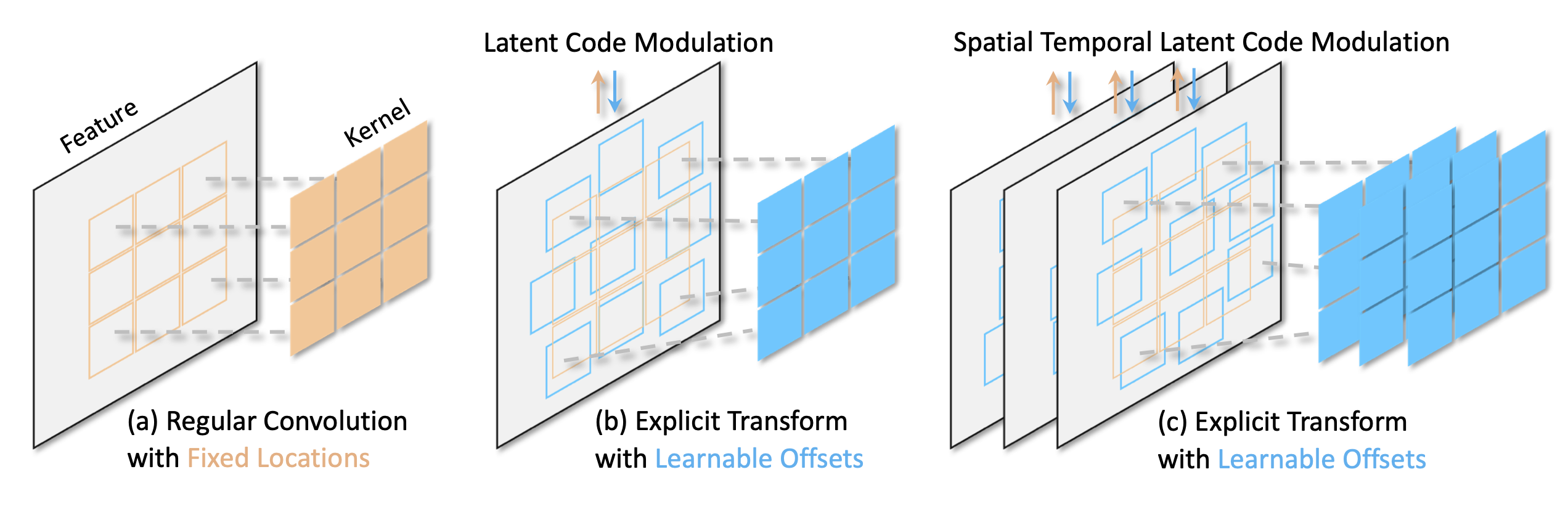
Learning Modulated Transformation in GANs
NeurIPS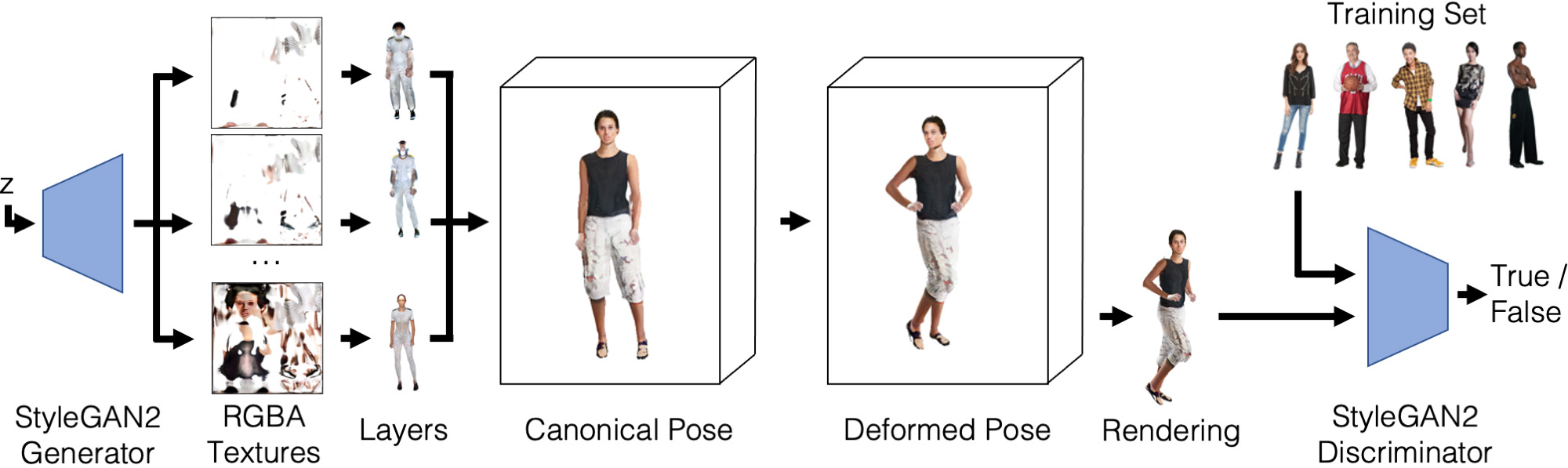
Efficient 3D Articulated Human Generation with Layered Surface Volumes
✨ 3DV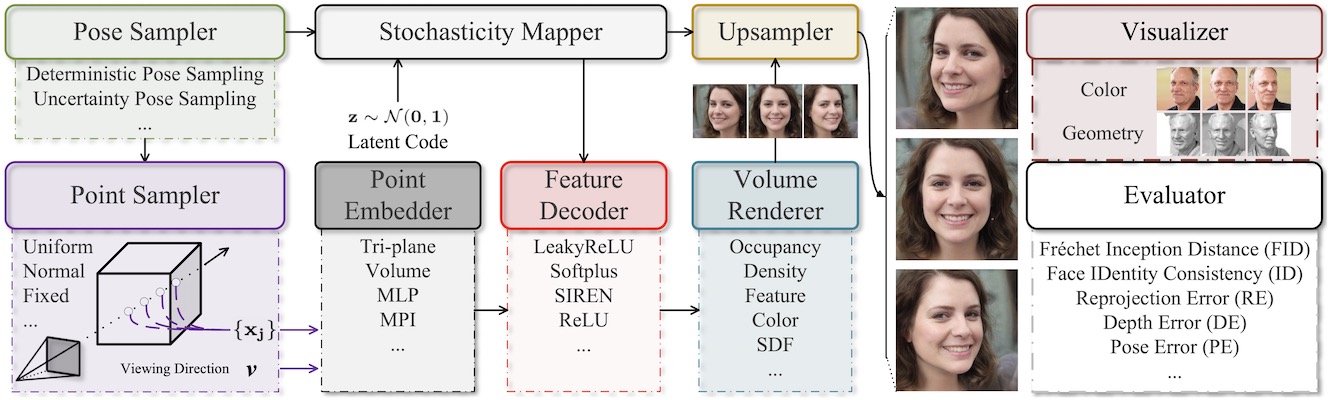
Benchmarking and Analyzing 3D-aware Image Synthesis with a Modularized Codebase
NeurIPS
3D Generation on ImageNet
✨ ICLR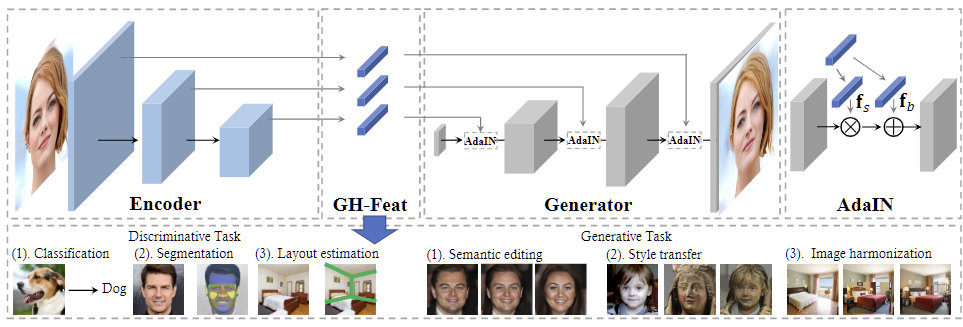
GH-Feat Learning Versatile Generative Hierarchical Features from GANs
TPAMI
Learning 3D-aware Image Synthesis with Unknown Pose Distribution
CVPR
DiscoScene Spatially Disentangled Generative Radiance Field for Controllable 3D-aware Scene Synthesis
✨ CVPR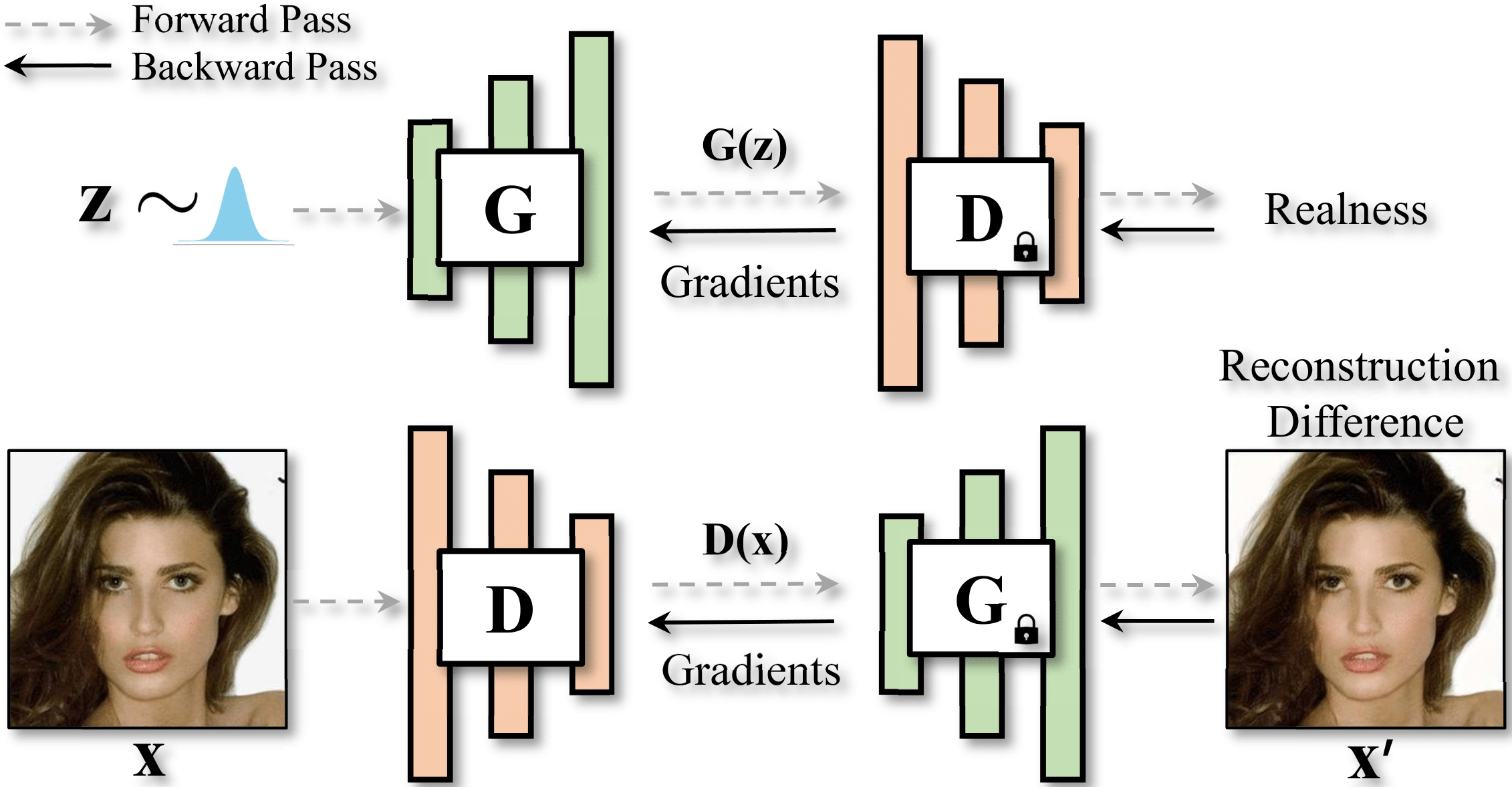
GLeaD Improving GANs with A Generator-Leading Task
CVPR
Towards Smooth Video Composition
ICLR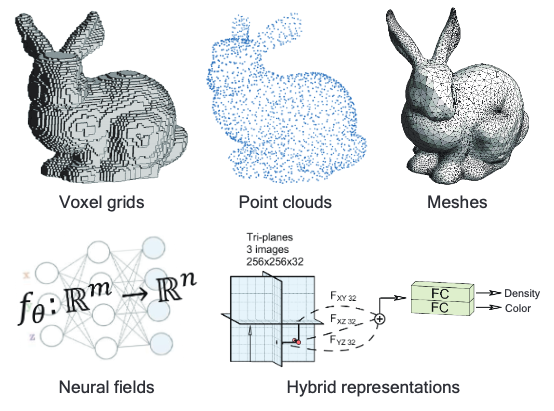
3D Generative Models A Survey
arXiv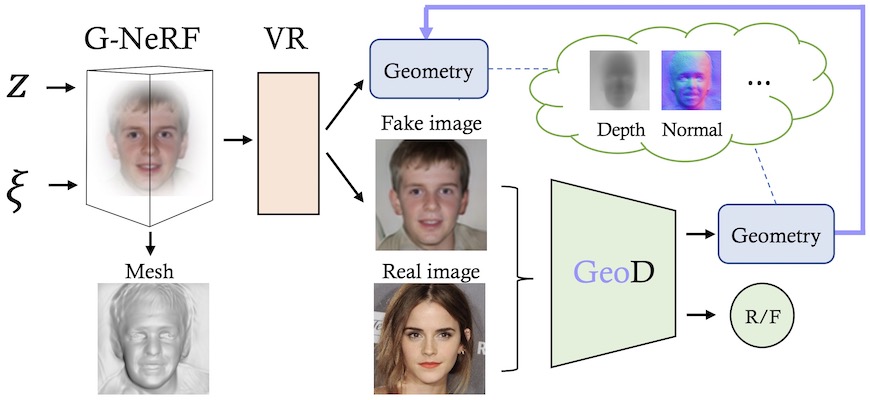
Improving 3D-aware Image Synthesis with A Geometry-aware Discriminator
✨ NeurIPS
Improving GANs with A Dynamic Discriminator
NeurIPS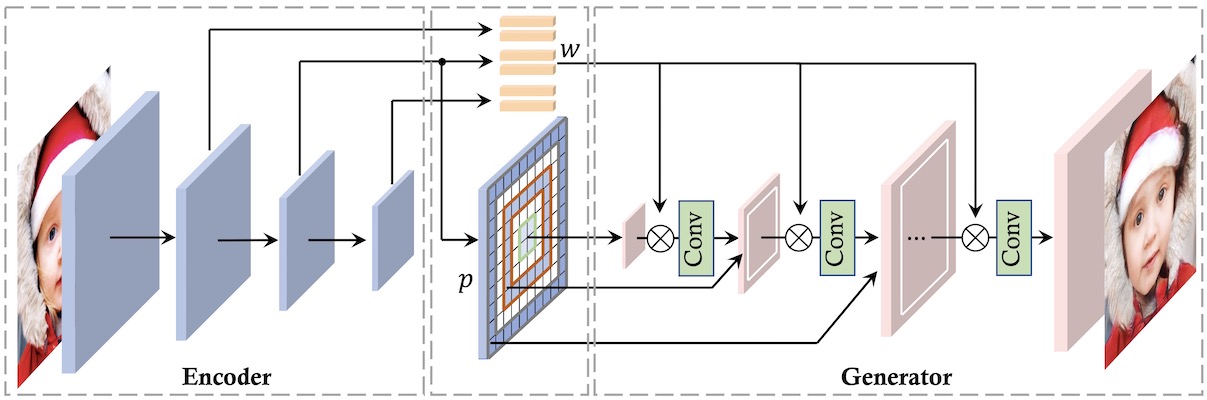
High-fidelity GAN Inversion with Padding Space
ECCV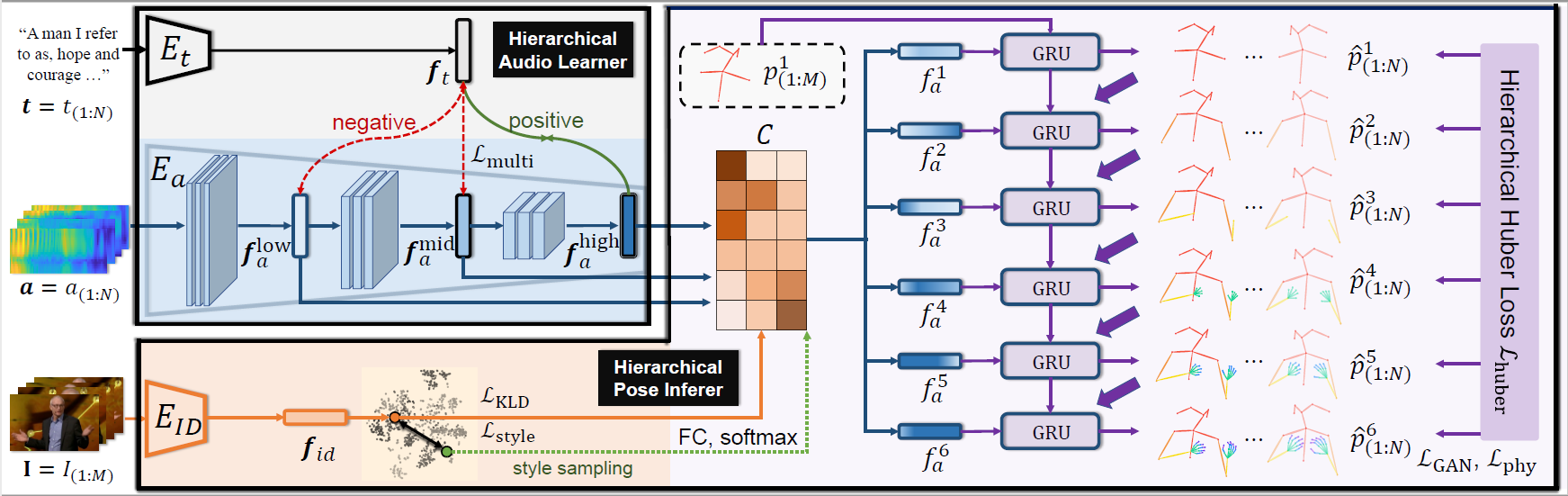
Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation
CVPR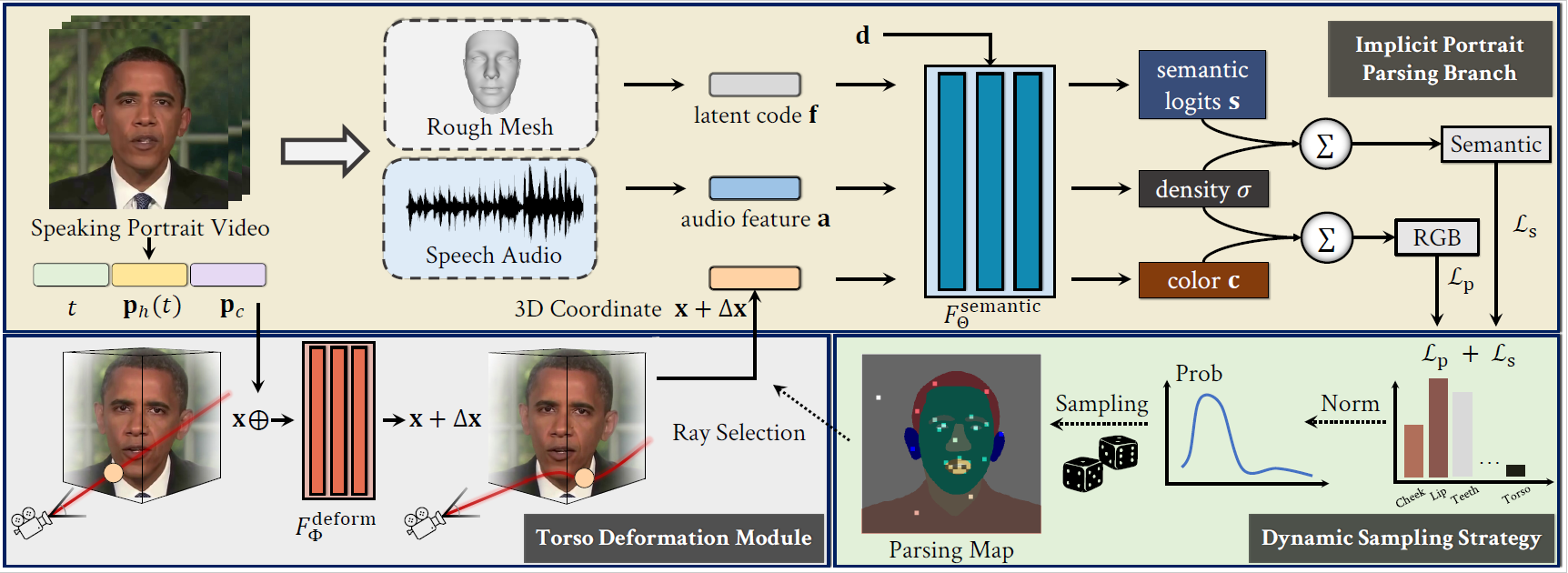
Semantic-Aware Implicit Neural Audio-Driven Video Portrait Generation
✨ ECCV
Region-Based Semantic Factorization in GANs
ICML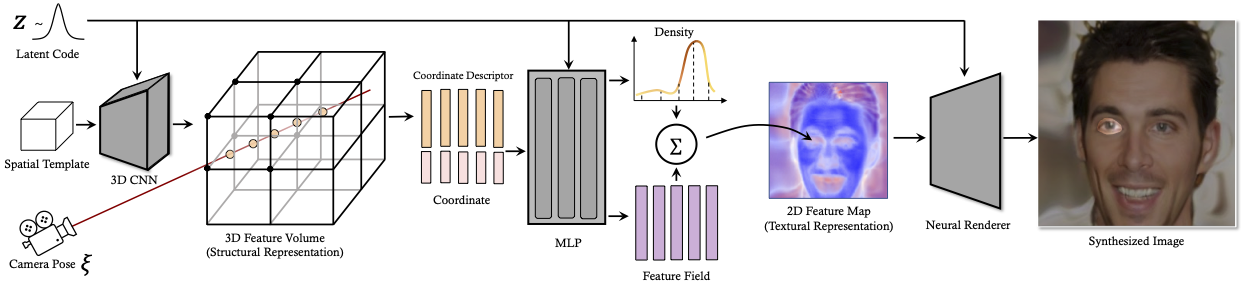
3D-aware Image Synthesis via Learning Structural and Textural Representations
CVPR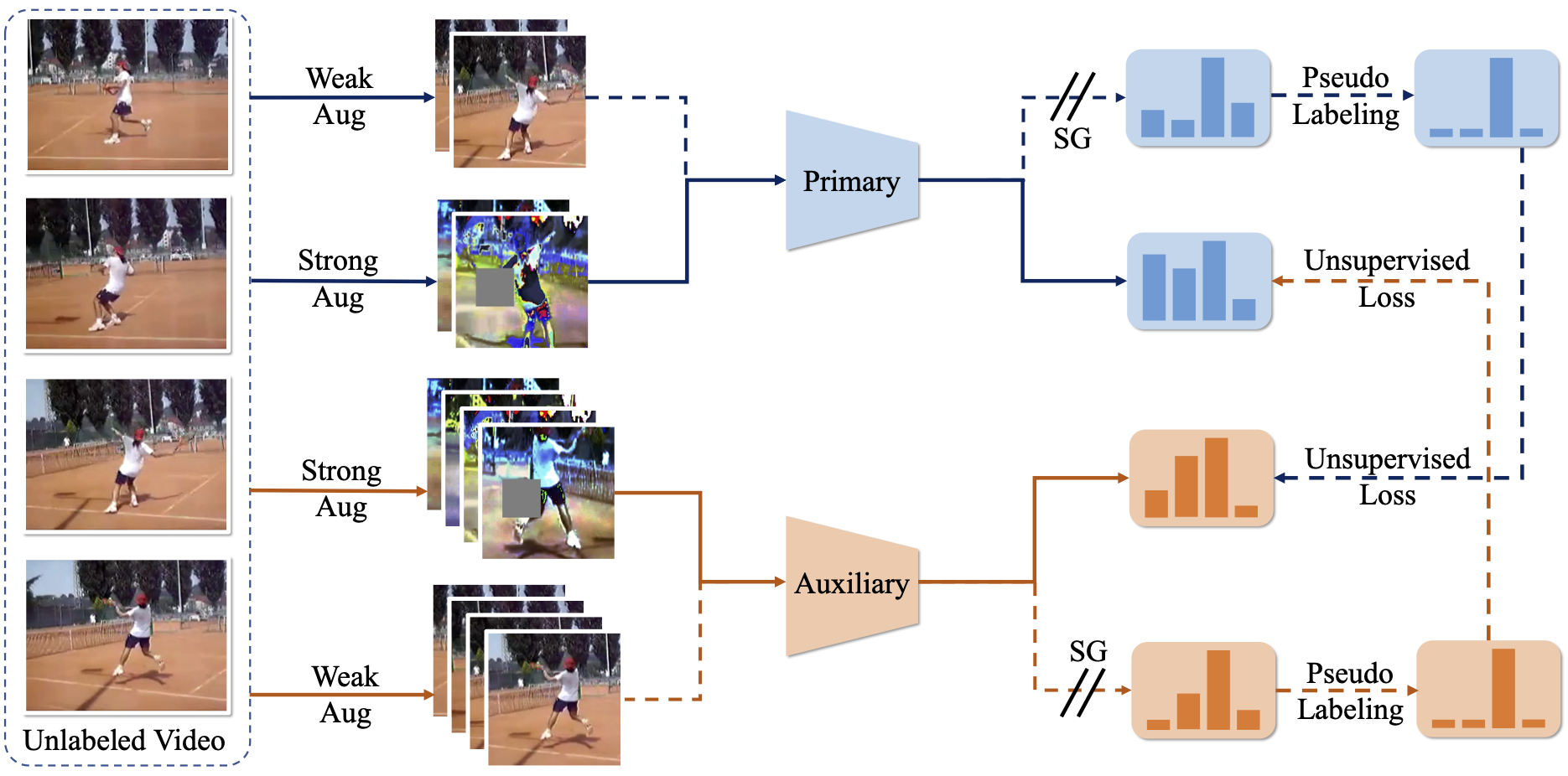
Cross-Model Pseudo-Labeling for Semi-Supervised Action Recognition
✨ CVPR
Improving GAN Equilibrium by Raising Spatial Awareness
CVPR
One-Shot Generative Domain Adaptation
ICCV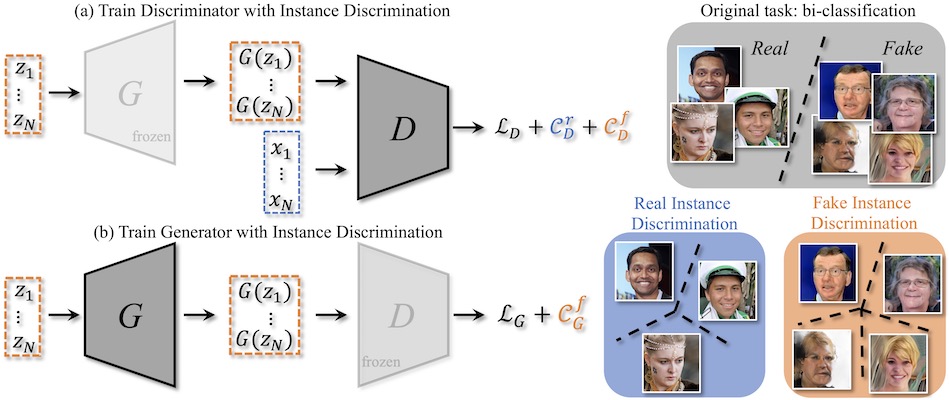
Data-Efficient Instance Generation from Instance Discrimination
NeurIPS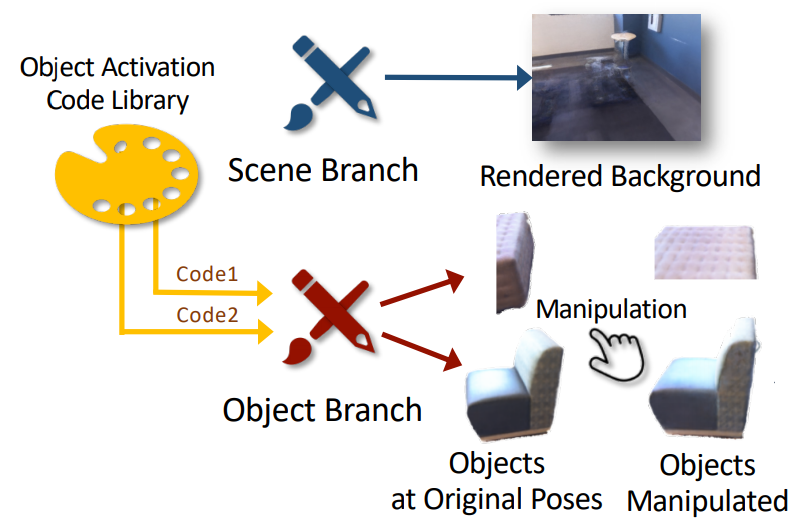
Learning Object-Compositional Neural Radiance Field for Editable Scene Rendering
NeurIPS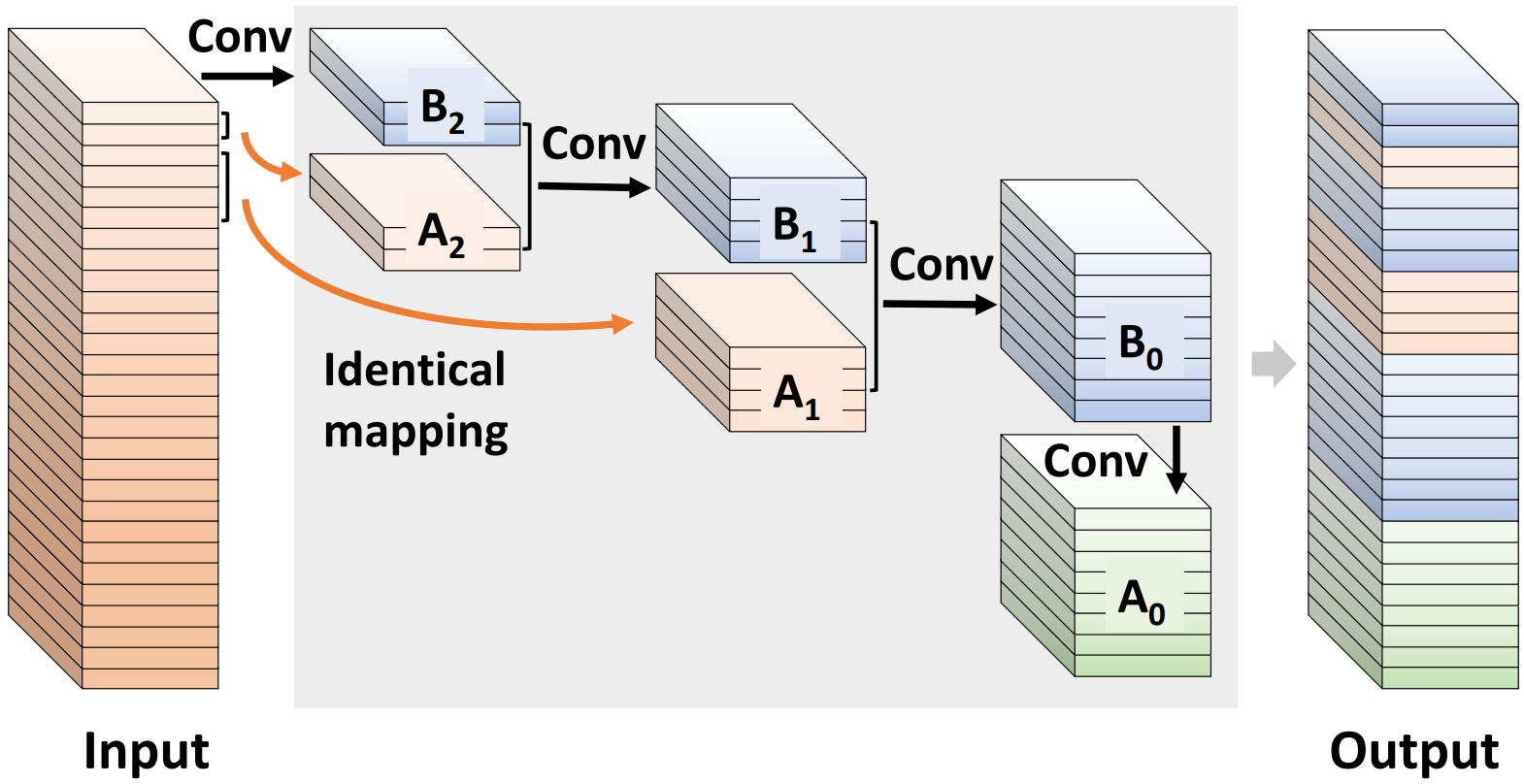
CompConv A Compact Convolution Module for Efficient Feature Learning
CVPRW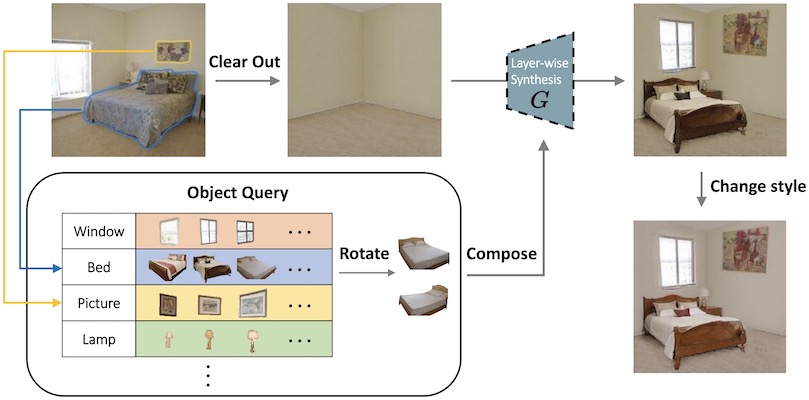
Decorating Your Own Bedroom Locally Controlling Image Generation with Generative Adversarial Networks
CVPRW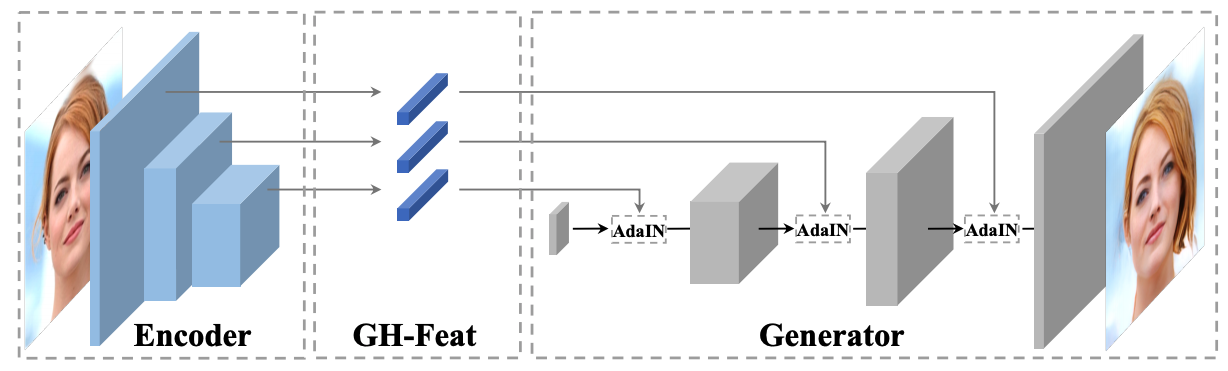
Generative Hierarchical Features from Synthesizing Images
✨ CVPR
Unsupervised Landmark Learning from Unpaired Data
arXiv
Video Representation Learning with Visual Tempo Consistency
arXiv
Temporal Pyramid Network for Action Recognition
CVPR
Dense RepPoints Representing Visual Objects with Dense Point Sets
ECCV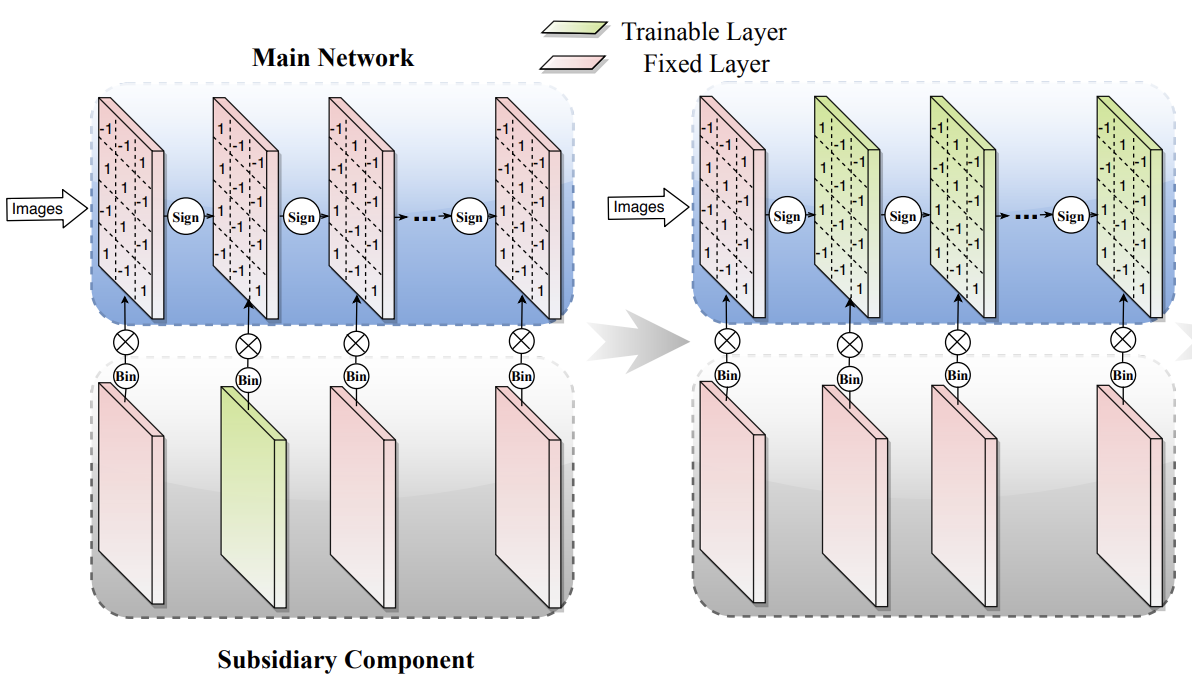
A Main/Subsidiary Network Framework for Simplifying Binary Networks
CVPRLingBot-Map: Geometric Context Transformer for Streaming 3D Reconstruction
LingBot-VA: Causal World Modeling for Robot Control
LingBot-World: Advancing Open-source World Models
LingBot-Depth: Masked Depth Modeling for Spatial Perception
Mixture of Contexts for Long Video Generation
Video World Models with Long-term Spatial Memory
Interspatial Attention for Efficient 4D Human Video Generation
CameraCtrl II: Dynamic Scene Exploration via Camera-controlled Video Diffusion Models
GroomLight: Hybrid Inverse Rendering for Relightable Human Hair Appearance Modeling
FLARE: Feed-forward Geometry, Appearance and Camera Estimation from Uncalibrated Sparse Views
Edicho: Consistent Image Editing in the Wild
Representing Long Volumetric Video with Temporal Gaussian Hierarchy
FiVA: Fine-grained Visual Attribute Dataset for Text-to-Image Diffusion Models
Flow as the Cross-domain Manipulation Interface
3DitScene: Editing Any Scene via Language-guided Disentangled Gaussian Splatting
Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control
CameraCtrl: Enabling Camera Control for Video Diffusion Models
GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation
Real-time 3D-aware Portrait Editing from a Single Image
BerfScene: Bev-conditioned Equivariant Radiance Fields for Infinite 3D Scene Generation
SceneWiz3D: Towards Text-guided 3D Scene Composition
Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
Gaussian Shell Maps for Efficient 3D Human Generation
DMV3D:Denoising Multi-View Diffusion using 3D Large Reconstruction Model
PF-LRM: Pose-Free Large Reconstruction Model for Joint Pose and Shape Prediction
Instant3D: Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model
Exploring Sparse MoE in GANs for Text-conditioned Image Synthesis
Learning Modulated Transformation in GANs
Efficient 3D Articulated Human Generation with Layered Surface Volumes
Benchmarking and Analyzing 3D-aware Image Synthesis with a Modularized Codebase
3D Generation on ImageNet
GH-Feat: Learning Versatile Generative Hierarchical Features from GANs
Learning 3D-aware Image Synthesis with Unknown Pose Distribution
DiscoScene: Spatially Disentangled Generative Radiance Field for Controllable 3D-aware Scene Synthesis
GLeaD: Improving GANs with A Generator-Leading Task
Towards Smooth Video Composition
3D Generative Models: A Survey
Improving 3D-aware Image Synthesis with A Geometry-aware Discriminator
Improving GANs with A Dynamic Discriminator
High-fidelity GAN Inversion with Padding Space
Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation
Semantic-Aware Implicit Neural Audio-Driven Video Portrait Generation
Region-Based Semantic Factorization in GANs
3D-aware Image Synthesis via Learning Structural and Textural Representations
Cross-Model Pseudo-Labeling for Semi-Supervised Action Recognition
Improving GAN Equilibrium by Raising Spatial Awareness
One-Shot Generative Domain Adaptation
Data-Efficient Instance Generation from Instance Discrimination
Learning Object-Compositional Neural Radiance Field for Editable Scene Rendering
CompConv: A Compact Convolution Module for Efficient Feature Learning
Decorating Your Own Bedroom: Locally Controlling Image Generation with Generative Adversarial Networks
Generative Hierarchical Features from Synthesizing Images
Unsupervised Landmark Learning from Unpaired Data
Video Representation Learning with Visual Tempo Consistency
Temporal Pyramid Network for Action Recognition
Dense RepPoints: Representing Visual Objects with Dense Point Sets